I saw whisper.cpp mentioned on Hacker News and I was intrigued. whisper.cpp takes an audio file as input, transcribes speech, and prints the output to the terminal. For some time I wanted to see how machine learning projects performed on my POWER9 workstation, and how hard they would be to get running. whisper.cpp had several properties that were interesting to me.
First, it is freely licensed, released under the MIT license and it uses the OpenAI Whisper model whose weights are also released under the MIT license. Second, whisper.cpp is a very compact C/C++ project with no framework dependencies. Finally, after the code and the model are downloaded, whisper.cpp runs completely offline, so it is inherently privacy-respecting.
There was one tiny build issue, but otherwise, it just built and
ran on PPC64. I was expecting to need dependent libraries and so
forth, but the code was extremely portable. However, I knew it was
running much slower than it could. A clue: the minor build failure was due to
a missing architecture-specific header for vector intrinsics
(immintrin.h) that wasn’t available for ppc64le
Debian.
I took the opportunity to learn PPC64 vector intrinsics. Thanks to the OpenPOWER initiative, freely-licensed, high-quality documentation was readily downloadable from https://openpowerfoundation.org (no registration, paywalls, click-throughs, JS requirements, etc.).
I did an initial implementation for POWER9 using the IBM Vector-Scalar Extension (VSX) and the transcription speed improved considerably; for the base model, the example transcription ran in about one tenth the time. Meanwhile, the upstream project had re-organized its intrinsics support, so I reorganized my implementation to fit in. This was trickier than I expected, because of how FP32/short packing and unpacking worked in VSX.
Here is a graph of the results:
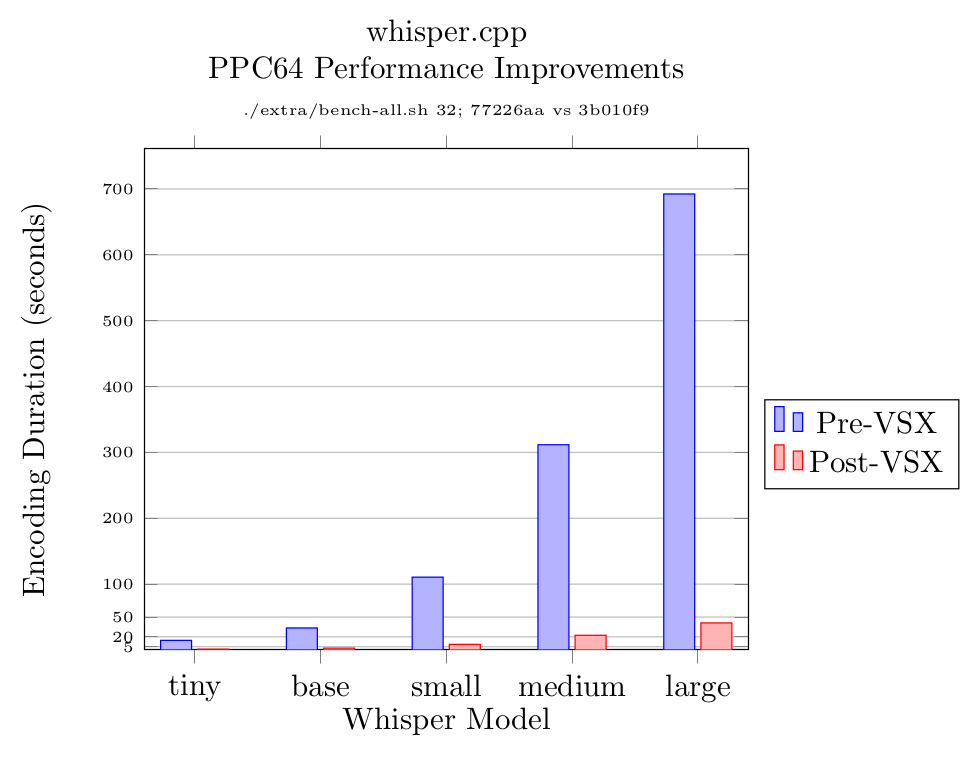
For the sake of completeness (and for my friends on #talos-workstation) I also added big endian support and confirmed that the example ran on my PPC64BE virtual machine.
I’m sure more optimizations are possible. I may try OpenBLAS (CPU) and/or ROCm (GPU) acceleration later. So far everything is running on the CPU. But I’m glad that, at least for the inference side, the Whisper model can attain reasonable performance on owner-controlled hardware like the Talos II.
One potential downside of Whisper’s trained-model approach (vs other transcription approaches, like Julius) is that for downstream projects, the model is pretty much unfixable if it has an issue. I have run whisper.cpp on real world materials with excellent results, especially with the large model. But if there are bugs, I don’t think fixing them is possible without retraining the model, which at least for Whisper, seems beyond the means of individuals.
I would like to thank Matt Tegelberg for evaluating whisper.cpp’s results against real world audio and for proof-reading this post.